1) The Backstory
Setting context: what went wrong and why it mattered
When a website stops showing up on Google, most people tweak keywords or install another plugin. On GrowWithConsultants.com, the on-page work looked solid, yet critical pages weren’t indexing.
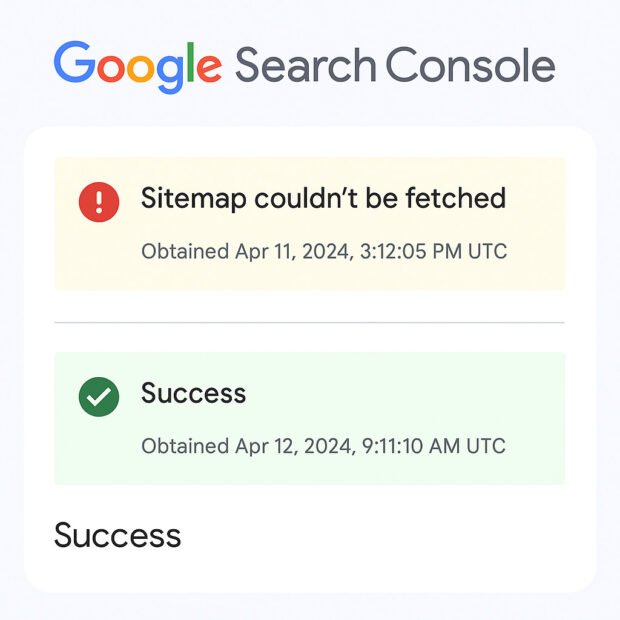
Google Search Console kept flashing: “Sitemap couldn’t be fetched.” Speed, schema, and internal links were already improved—so the block had to be deeper.
- Fresh content and basic SEO were in place.
- Key pages still didn’t appear in Google’s index.
- Multiple “quick fixes” from agencies didn’t move the needle.
Mindset shift: stop treating symptoms; verify what Google actually sees.
That means inspecting live
/robots.txt, the sitemap response, and crawl permissions.
3) The Technical Diagnosis
Verify before fixing — crawl, fetch, inspect
We approached this like a forensic audit. Tools help, but the truth lives in live responses.
- Robots.txt check: Opened
/robots.txtdirectly in browser to view the actual served file. - GSC “Test Live URL”: Confirmed crawl & indexing status (blocked vs allowed).
- Screaming Frog: Full crawl to detect redirect chains and any “Blocked by robots.txt”.
- Headers & CDN: Reviewed response headers and Cloudflare rules influencing text files.
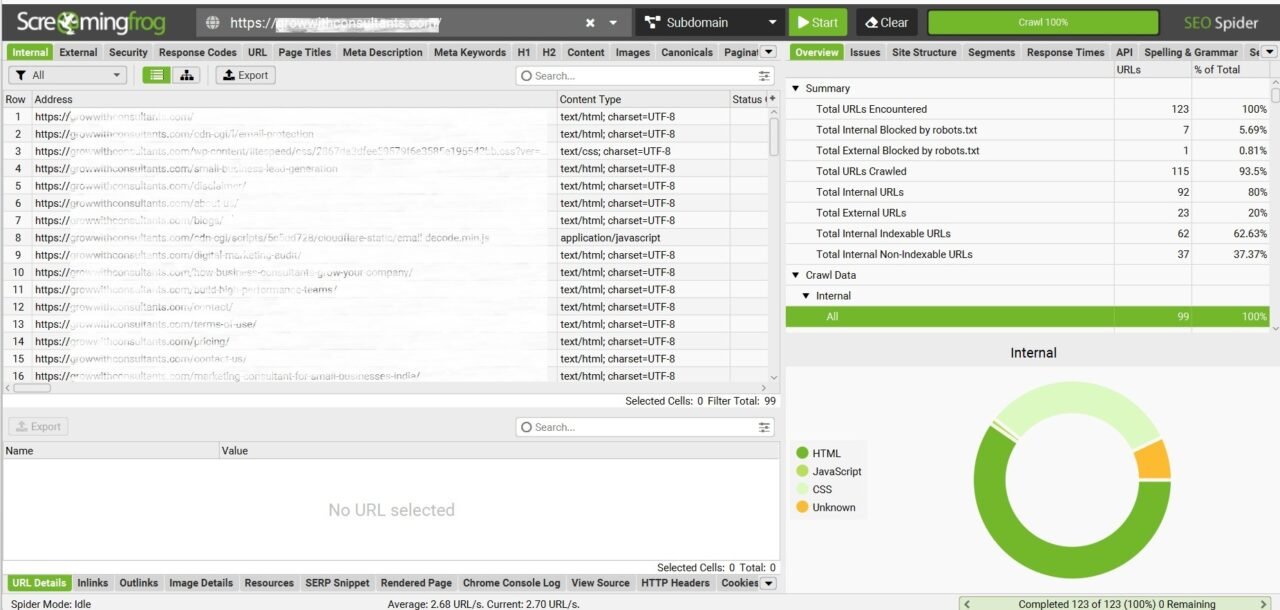
Finding: The robots.txt wasn’t just “miswritten.” It was overridden by a server/CDN rule that injected policy text,
confusing Googlebot.
My job isn’t just to review what’s done in SEO — it’s to uncover what’s missing in your business protocols.
Whether it’s your website setup, technical SEO, Local SEO, GMB, content, or server configuration —
our holistic approach pinpoints hidden issues and fixes them to drive real leads and lasting business growth.

Ameet Mukherji
Business Growth Consultant • Technical SEO & Systems
260% ↑ Indexed URLsin 3 weeks
+261% Impressionspost fix
0 → 8 Valid Sitemapsclean & verified
48 hrs Crawl Restoreafter root-cause fix
“Most SEO fails aren’t keyword problems. They’re system problems. Diagnose first, then optimize. If Google can’t see your site, nothing else matters.”